GPT와 원만하게 대화로 해결했습니다. 🤝
지금 Hugging Face Space에서 플레이해볼 수 있습니다.
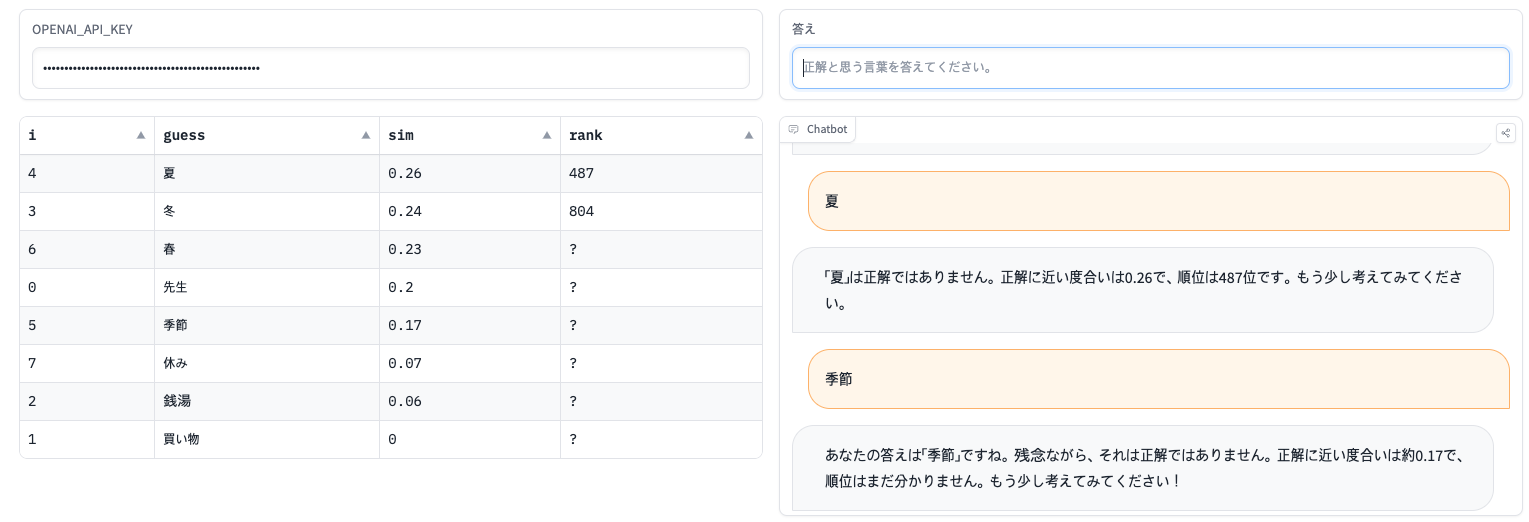
0. 지난 이야기: 그 동안의 결과물
- 일본어 버전 릴리즈
- 정답 단어 목록 업데이트
- 유사도 기반 힌트 기능 구현
1. [NEW] 주고받기 모드
FlowGPT와 Hackaprompt에서 복잡한 태스크를 위한 다양한 프롬프트를 보며, semantle의 진행에도 활용해보기로 했습니다.
2. function calling과 프롬프트
2.1. function calling
게임 진행에 필요한 데이터나 게임 규칙을 한 번에 모두 전달하면 프롬프트가 너무 길어집니다. 토큰을 낭비하게 될 뿐더러, 모델이 내용을 파악하기도 어려워집니다.
function calling를 통해, 모델이 함수를 이용하여 필요한 데이터를 가져올 수 있도록 만들었습니다. 단어 유사도를 가져오는 일 외에, 정답 단어를 확인하거나 규칙을 읽는 일도 함수로 지정했습니다.
guess_word = {"name": "guess_word",
"description": "Use this function to check if a guessed word is the correct answer or not, and if incorrect, calculate a score and a rank of the guess word.",
"parameters": {
"type": "object",
"properties": {
"word": {
"type": "string",
"description": "A single Japanese word to guess, which is can be a noun, verb, adverb or adjective. e.g. 空, 近い, 行く, etc."
},
},
"required": ["word"]
}}
lookup_answer = {"name": "lookup_answer",
"description": "Use this function to check the correct answer of today's puzzle.",
"parameters": {
"type": "object",
"properties": {},
}}
read_rule = {"name": "read_rule",
"description": "Use this function to read the game rule for clarification of your response.",
"parameters": {
"type": "object",
"properties": {},
}}더불어 한 번의 호출에 여러 함수를 필요한 만큼 불러올 수 있도록 함수를 실행하게 하는 코드는 recursive하게 작성했습니다.
2.2. 프롬프트
보통 assistant의 역할, 수행할 작업 내용, 유저 입력 형식 등을 항목으로 구성하여 프롬프트를 작성합니다. semantle이란 게임은 어떤 fine-tuning도 되지 않은 LLM에게는 낯선 내용이기 때문에, 게임의 진행 방식을 상세히 알려줄 필요가 있었습니다. 또한, 유저는 다양한 의도의 메시지를 전달할 수 있어 복잡한 작업이 됩니다.
모델이 게임을 잘 이해할 수 있도록 2가지 방식으로 프롬프트를 작성했습니다. 아래에는 한국어로 작성되어 있지만, 실제로는 일본어로 작성했습니다.
작업 과정을 상세하게
- 유저의 메시지를 받은 뒤 어떤 사고 과정을 거쳐야 하는지 상황별로 상세히 전달합니다.
- 게임 소개 내용은 아래 메시지에 추가하여 별도로 전달했습니다.
assistant의 작업 과정- 발화 의도 파악: 유저의 메시지를 읽고 다음 중 어떤 것을 원하는지 파악합니다.
- 정답 추측
- 힌트 제공
- 정답 확인
- 정답 추측
- 게임 진행
- 정답을 추측하는 경우, 사전 정의된 함수를 사용해 추측한 단어의 점수와 순위를 구합니다.
- 점수와 순위가 없으면 추측 기록에 추가하지 않고, 게임에 없는 단어라고 안내합니다.
- 그렇지 않으면 추측 기록에 반환 결과를 추가하고,
- 순위가 ’정답!’인 경우, 정답을 맞혔다고 안내합니다.
- 그렇지 않으면 업데이트 된 추측 기록을 보고 플레이 상황에 대해 코멘트합니다.
- 순위가 ’정답!’인 경우, 정답을 맞혔다고 안내합니다.
- 힌트를 원하는 경우,
- ‘어떠한’ 힌트인지 제시되었다면 그에 맞춰 제공합니다.
- 막연히 힌트를 요구한다면 적당히 설명해줍니다.
- 정답 확인을 요구하는 경우, A. 정답을 알면 게임이 끝나므로, 포기하려는 것인지 확인합니다.
- 포기한다고 재차 말하면 정답을 알려주고 게임을 끝냅니다.
- 포기한다고 재차 말하면 정답을 알려주고 게임을 끝냅니다.
- 그 외 게임과 무관한 내용은 답변하지 않도록 합니다.
- 정답을 추측하는 경우, 사전 정의된 함수를 사용해 추측한 단어의 점수와 순위를 구합니다.
게임의 컨셉만 간결하게
첫 번째 버전은 구조적으로 정리는 되어 있었지만, 내용이 길어서인지 모델이 내용을 놓치는 경우가 많았습니다.
두 번째에는 assistant의 역할만 간단히 작성하여 전달했습니다. 추가로, 유저 입력 앞에 접두어를 붙여 정답을 추측하는 상황으로 판단하도록 유도했습니다.
당신은 <imitoru>라는 게임의 진행자입니다. 보통 유저는 답을 말하지만, 종종 게임에 관한 힌트를 요청합니다. 짧지만 정중하게 대답해주세요. 힌트를 알려줄 때에는 반드시 정답을 감춰주세요. 절대 정답을 말해서는 안 됩니다. {'role': 'system', 'content': system_content} {'role': 'user', 'content': '답: '+user_input}게임의 컨셉과 진행 방식을 게임 설명서 형식으로 작성해 두고, 모델이 필요할 때 호출할 수 있도록 했습니다.
#### 게임 방법 숨겨져 있는 오늘의 단어를 맞추는 게임입니다. 정답으로 추측되는 단어를 맞히면 정답 여부를 알 수 있습니다. 정답이 아닌 경우, 정답에 얼마나 가까운 정도와 순위를 알 수 있습니다. 정답에 가까운 정도는 단어의 의미, 문맥, 단어의 언어적 특성 등에 따라 결정됩니다. 추측한 단어의 정답에 가까운 정도와 순위를 참고하여 계속 정답을 맞혀보세요. #### 힌트에 대해 만약 정답이 어렵거나 게임 규칙을 이해하기 어렵다면 힌트를 요청할 수 있습니다. 정답에 대한 예문, 정답과 어떤 단어의 의미나 문법적 공통점 등 다양한 정보를 들을 수 있습니다. 힌트 내용에 정답은 포함되어 있지 않습니다. #### '가까운 정도와 순위'에 대해 '근접도'는 정답 단어와의 유사도를 -100에서 +100까지 숫자로 표시합니다. '순위'는 데이터베이스에서 가까운 정도의 상대적인 위치로, 3순위에서 1000순위까지 나타냅니다. '가까운 정도('sim')가 100인 단어가 정답입니다.
3. 주요 결과
- 접두어 사용으로 쉬워진 의도 파악
모델이 갑자기 ’묻다’이라는 단어를 들으면 어떻게 대응할까요? 오늘의 정답 단어가 ’묻다’이라고 추측하는 상황일 수도 있고, 게임에 대해 질문하고 싶은 것일 수도 있습니다. 이런 단어 외에도 여러 단어들이 다양한 의도로 해석될 가능성이 있습니다. 그렇다고 해서 정답을 외칠 때마다 ’정답은 <묻다>인가요?’라고 물어보기에는 자연스럽지도 않고, 사용하기 불편합니다.
접두어로 답:을 추가한 것만으로 의도에 어긋나는 답변을 하는 경우가 크게 줄었습니다. 힌트를 요청할 때에도 대체로 의도를 잘 파악합니다. 힌트를 요청할 때에는 비교적 길고 완성된 문장으로 말하게 되므로, 답:이라는 글자에 크게 집중하지 않는 것 같습니다. 간혹 힌트를 요청하는 문장에서 일부 단어를 평가하는 일이 벌어지기는 하지만, 가장 빠르고 정확한 대응이 필요한 ‘추측’ 작업을 잘 수행할 수 있게 되었습니다.
작업해야 할 내용을 명확히 전달하기 위해 접두어를 사용하는 경우는 일반적입니다. 하지만 이번 프로젝트에서는 모델이 사용자의 입력을 통해 작업 내용을 정해야 하는 상황이 있어 처음부터 사용하지는 않았습니다. 하지만 입력이 조금만 길어지면 다른 프롬프트를 곧잘 무시하는 특성 덕분에1 복잡한 체인이나 파이프라인 설계 없이 간편하게 만들 수 있었습니다.
1 사용자가 이러한 특성을 악용해 의도에 어긋나는 입력을 시도하는 것을 방지하기 위해 post-prompting, sandwitch defense과 같은 방어 전략을 사용하기도 합니다. Learn Prompting에서 다양한 방어 전략을 보실 수 있습니다.
- 함수를 활용한 정확한 정보 전달
사전 프롬프트로 진행에 필요한 데이터, 특히 정답이나 규칙을 전달할 경우, 잘못된 대답을 하는 경우가 많았습니다. 정답이 아닌데 정답이라고 설명하는 것은 치명적인 오류였습니다. 아무래도 사용자 입력과 함수 수행을 위한 프롬프트가 쌓이면서 처음 전달했던 게임 정보에 집중하지 못하는 것 같았습니다. 정답이나 규칙을 함수로 불러올 수 있게 바꾼 뒤로, 응답을 만드는 과정에서 정보를 다시 한 번 확인하여 내보내는 모습을 확인할 수 있었습니다.
사용할 수 있는 함수를 다양하게 제공하면서 프롬프트도 간결하게 만들 수 있었습니다. 필요한 정보는 함수로 호출하여 받기 때문에, 사전 프롬프트에서는 기본적인 정보만 제공하도록 바뀌었습니다. 전체적으로 프롬프트의 양을 줄일 수 있었는데요, 현재는 게임 규칙을 한 번에 불러오도록 하고 있지만 제목에 따라 나누어 불러올 수 있게 하면 조금 더 줄일 수 있을 것 같습니다.
4. 마무리
프로젝트 초반에는 LLM을 내 마음대로 조종하기 위한 디테일한 프롬프트와 파이프라인을 주로 고민했습니다. 아무리 상세하게 설명해도 지시를 잘 이해하지 못하고 잘못된 일을 하기 일쑤였으니까요. (말 안 듣는 자식을 항상 타박만 하고 정작 자식과 소통할 줄 모르는 부모의 모습…) 하지만 여러 함수를 제공하고 아주 짧은 접두어를 붙여 간결하게 정리가 되었습니다. 결과물이 나온 것도 중요하지만, LLM과 원만하게 소통하는 방법을 배운 게 가장 큰 성과라는 생각이 듭니다.